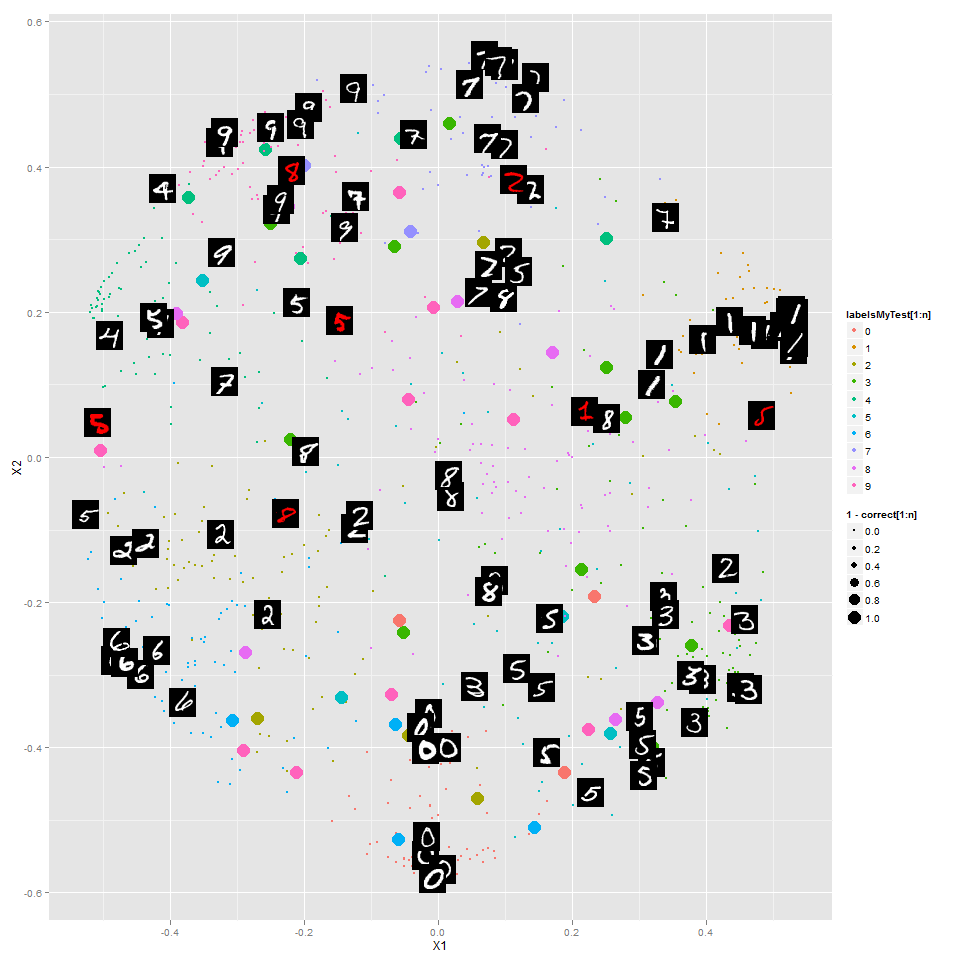
- Have a data set
- Create a set of fake data by permuting the columns randomly -- each column will still have the same distribution, but the relationships are destroyed.
- Train a random forest to distinguish the fake data from the original data.
- Get a "proximity" measure between points, based on how often the points are in the same leaf node.
- Embed the points in 2D in such a way as to distort these proximities as little as possible.
I decided to try this in a case where I would know what the outcome should be, as a way of thinking about how it works. So I generated 931 images of diamonds varying in two dimensions:
- Size
- Position (only how far left/right)
Then I followed the above procedure, getting this:
Neat! The random forest even picked up on a feature of this space that I wasn't expecting it to: for the same difference in position, small diamonds need to be closer to each other than large diamonds. None of my diamonds have a diameter smaller than 4 pixels, but imagine of the sizes got so small the diamond wasn't even there -- then position wouldn't matter at all of those diamonds.
I set one column of pixels to random values, and the method still worked just as well. (Which makes sense, as the random forest only cares about pixels that help it distinguish between diamonds and non-diamonds.)
A cool technique that I'd love to try some more! For one, I'd like to understand better how it differs from various manifold learning methods. One nice feature is that you could easily use this with a mix of continuous and categorical variables.
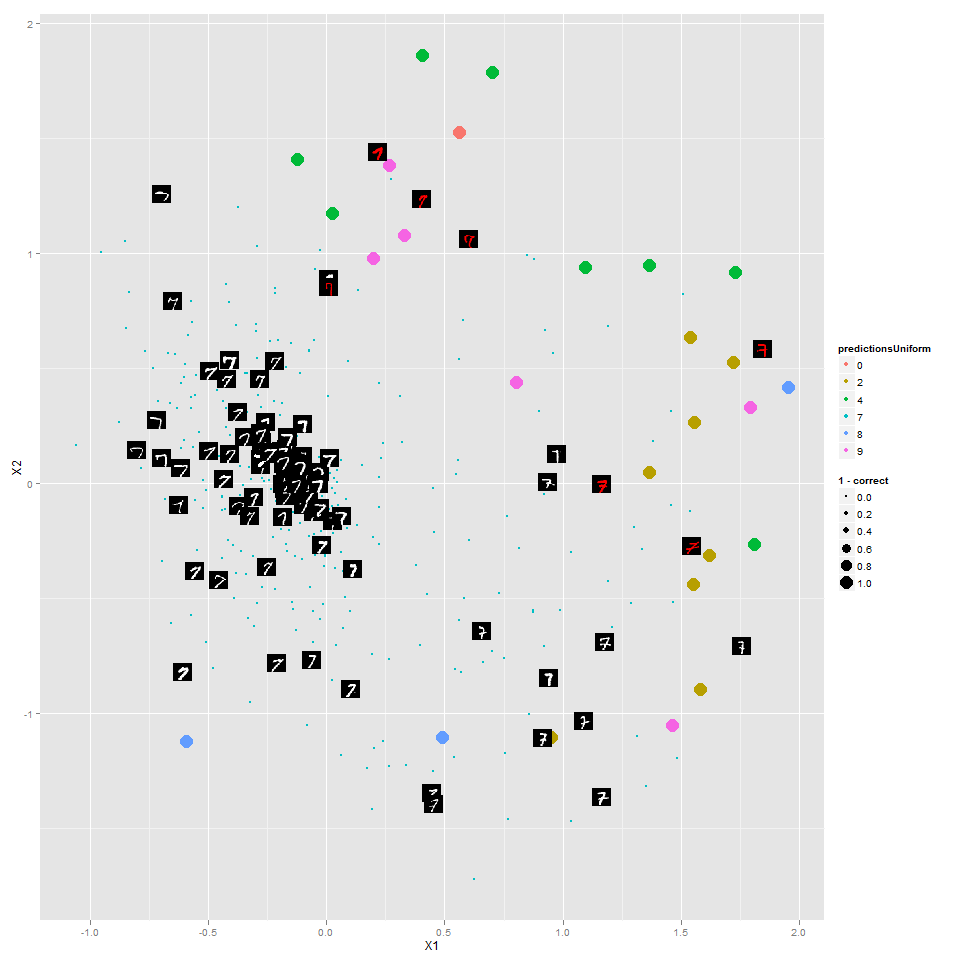
Note that starting with Euclidean distance between images (as vectors in R^2500) and mapping points to 2D doesn't seem to produce anything useful: