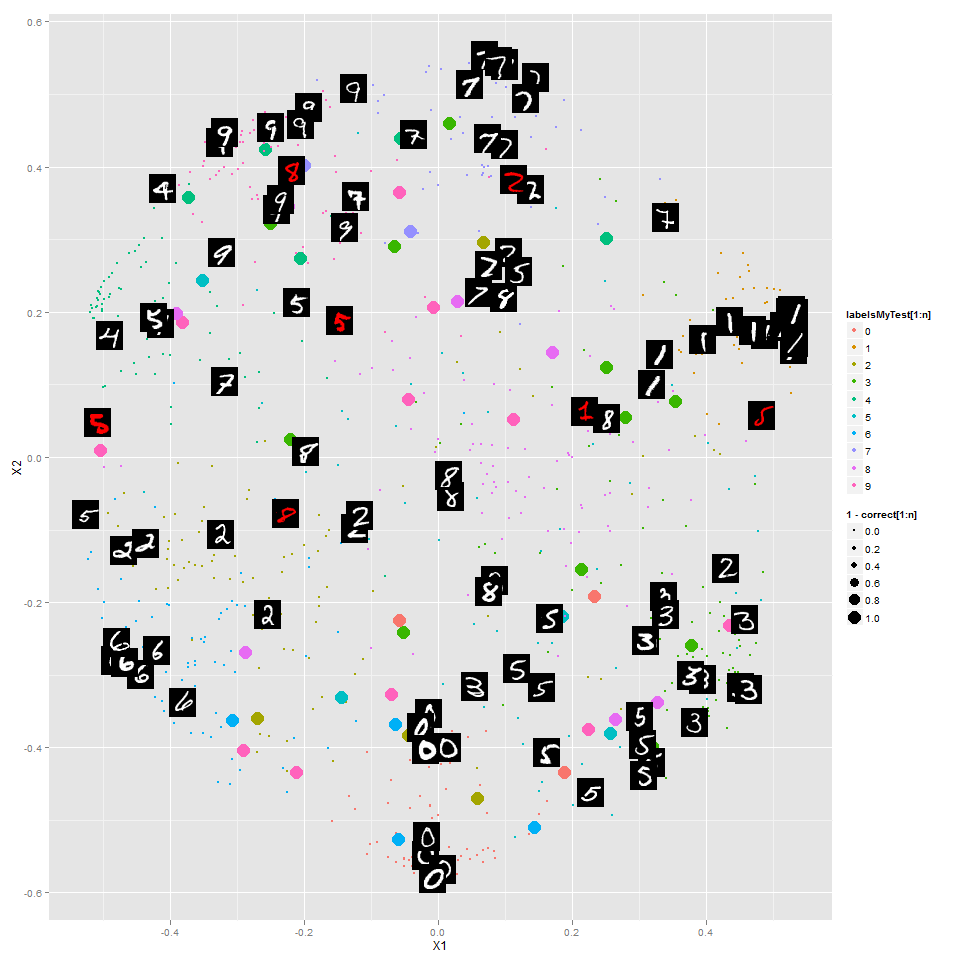
This time I looked at the digits data set that Kaggle is using as the basis of a competition for "getting started". The random forest is trained to classify the digits, and this is an embedding of 1000 digits into 2 dimensions preserving proximities from the random forest as closely as possible:
Here's the same but just for the 7's:
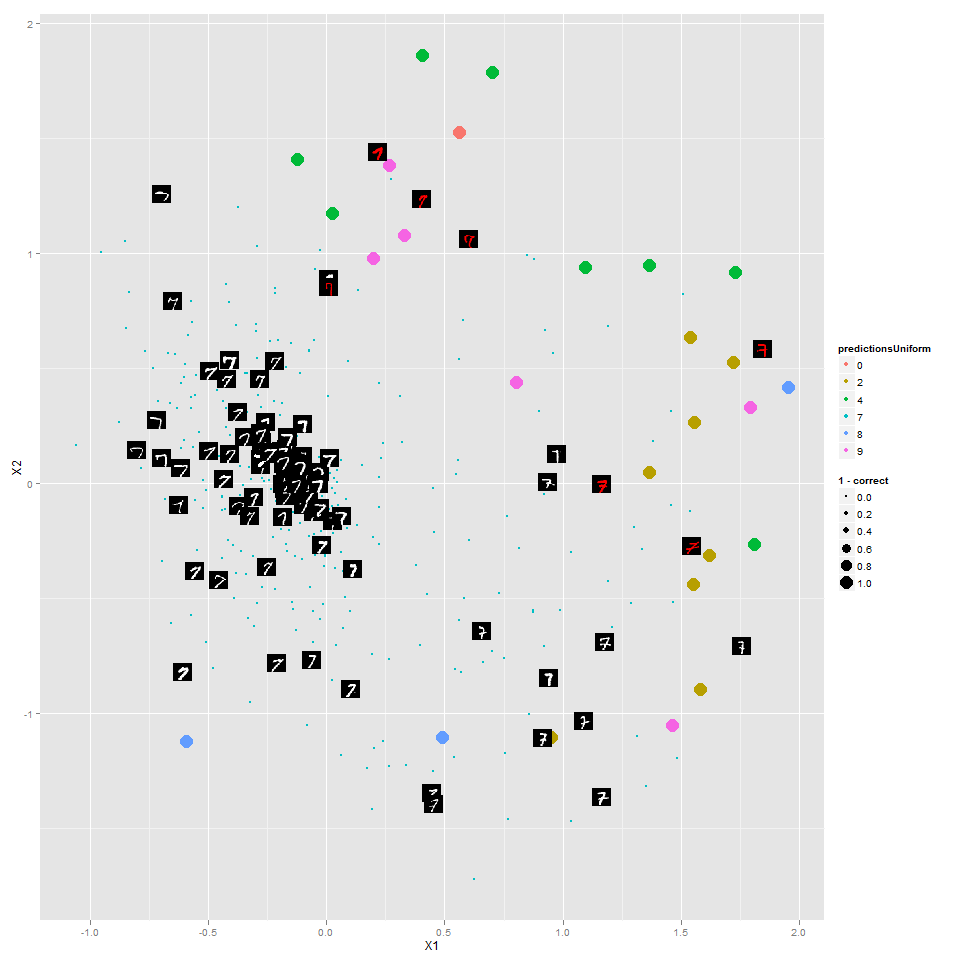
The random forest has done a reasonable job putting different types of 7's in different areas, with the most "canonical" 7's toward the middle.
You can see all of the other digits http://www.learnfromdata.com/media/blog/digits/.
Note that this random forest is different from the one in my last post -- here it's built to classify the digits, not separate digits from non-digits. I wonder what kind of results a random forest to distinguish 7's from non-7's would look like?
Code is on Github.
Great job!!Can you explain what " 2 dimensions preserving proximities from the random forest as closely as possible" means..like what metric you used to determine that it stays as close as possible?
ReplyDeleteThis is an interesting article that demonstrates how a Random Forest model can be visualized and interpreted when classifying handwritten digits. The author effectively explains the importance of understanding model behavior rather than treating machine learning algorithms as black boxes. The discussion provides valuable insights into classification techniques, feature importance, and the role of visualization in improving model interpretability.
DeleteThe article focuses on classification models, predictive analytics, and algorithm-driven decision making using Random Forests. These concepts are highly relevant to Machine Learning Projects for Final Year, where intelligent systems are developed to recognize patterns, classify data, and generate accurate predictions across a variety of applications.
DeleteThis is a broad scope of dialects and toolboxs utilized by Data Scientists. ExcelR Data Science Courses
ReplyDeleteShould there be a workable carbon credit, farmers and land stewards that chose to invest in forests could begin to see the financial returns on these personal investments that benefit our entire society.Forestry Mulching in Virginia
ReplyDeleteA very clever idea. discoverziehler.com
ReplyDeleteThis is interesting! Wish to do that myself!
ReplyDeletehttps://www.charlottejunkremovalservice.com/
Attend The data science course in Hyderabad From ExcelR. Practical data science course in Hyderabad Sessions With Assured Placement Support From Experienced Faculty. ExcelR Offers The data science course in Hyderabad. data science course in Hyderabad
ReplyDeleteVery nice blogs!!! i have to learning for lot of information for this sites…Sharing for wonderful information.Thanks for sharing this valuable information to our vision. You have posted a trust worthy blog keep sharing, data science online training
ReplyDelete
ReplyDeleteIts as if you had a great grasp on the subject matter, but you forgot to include your readers. Perhaps you should think about this from more than one angle.
data science course
This is a really explainable very well and i got more information from your site.Very much useful for me to understand many concepts and helped me a lot.Best data science courses in hyerabad
ReplyDeletekeep up the good work. this is an Ossam post. This is to helpful, i have read here all post. i am impressed. thank you. this is our site please visit to know more information
ReplyDeletedata science training in courses
But AI is also poised to reinvent other areas of life. One is health care. Hospitals in India are testing software that checks images of a person's retina for signs of diabetic retinopathy, a condition frequently diagnosed too late to prevent vision loss. data science course in india
ReplyDelete